食材をベクトル化する研究を紹介.
論文理解の助けになれば幸い.
FlavorGraphとは
食材と化合物を同じグラフ上で表現し,異種グラフ特化型の埋め込み手法に入れることでそれぞれ食材の分散表現を得ている.
論文中ではこの構築している異種グラフのことをFlavorGraph[1]と呼んでいる.
埋め込み手法は異種グラフ埋め込み手法としては初期のものである Metapath2vec[2]を使っている.
その中で新たな層を追加する提案もしている.
性能は普通のword2vecなどの文字埋め込みや食材に含まれる成分の値を特徴量としたものと比べ精度が良いとしている.
化合物の構造まで考慮した点が売りだと思われる.
一年も立たずうちに被引用数も伸びているので食材埋め込みの中では注目されていると言えるのではないか
詳細は元論文を読もう
www.nature.com
背景
"Food Pairing" といういわゆる食材同士をどう組み合わせて料理を作ろうかと考えるテーマ.
これまでシェフの直感で見つけられていた食材の相性を機械で行えるようにしましょうという流れ.
既存手法との差異は,レシピのデータかつ化合物のデータを用いて埋め込みをした点と,既存のグラフ埋め込み手法に層を追加した点.
グラフの構成データ
グラフの構成データは食材がRecipe1M,これは画像系の研究でよく見られるものだけど.レシピと食材名だけ取ってきている.
化合物はFlavorDBとHyperFoodsから.これらは食材と化合物の関係を示したデータベースだが,どういう閾値 で関係性を見ているのかは各自参照して欲しい.
以下の表がその要素と数.(わかりやすくするためそれぞれの要素に形式的な記号がつけられている,ありがたい)
グラフの構成要素とその数
ここで注意すべき点が食材ノードが二種類あるところ.(HとN)
Hは化合物との関係性が貼られている食材,要は化学データベース内に存在している食材とレシピ内の食材で照合し,一致した食材になる.Nはそれ以外の食材.
(余談)
頭文字のHはハブ(hub)のHからきていて,複数の化合物のハブ的役割を果たす食材のような意味合いだと思う
異種グラフ埋め込み
構築したFlavorGraphを異種グラフ特化の埋め込み手法のMetapath2vecに入れる.
Metapath2vecの仕組みは以下が参考になった.
論文紹介 / metapath2vec: Scalable Representation Learning for Heterogeneous Networks - Speaker Deck
異なるカテゴリの関係をベクトルに表現できるが,その場合パスの生成ルールであるメタパスを設定必要がある.
この研究では以下の二つを設定.
化合物(C)から始まり他の化合物(C')で終わるパス
食材(H)から始まり,化合物を通りつつ他の食材(H’)で終わるパス
ここで着目したいのが食材(H)から始まっている点.
全省のデータ説明でも述べたが,食材には化合物とのエッジが貼られているものと貼られていないものがある.
この二つのメタパスを設定することで,グラフ学習内で混ざってこれらが学習されるので(H)に対して化合物の関係の情報を渡すことができる(メタパスの性質上)
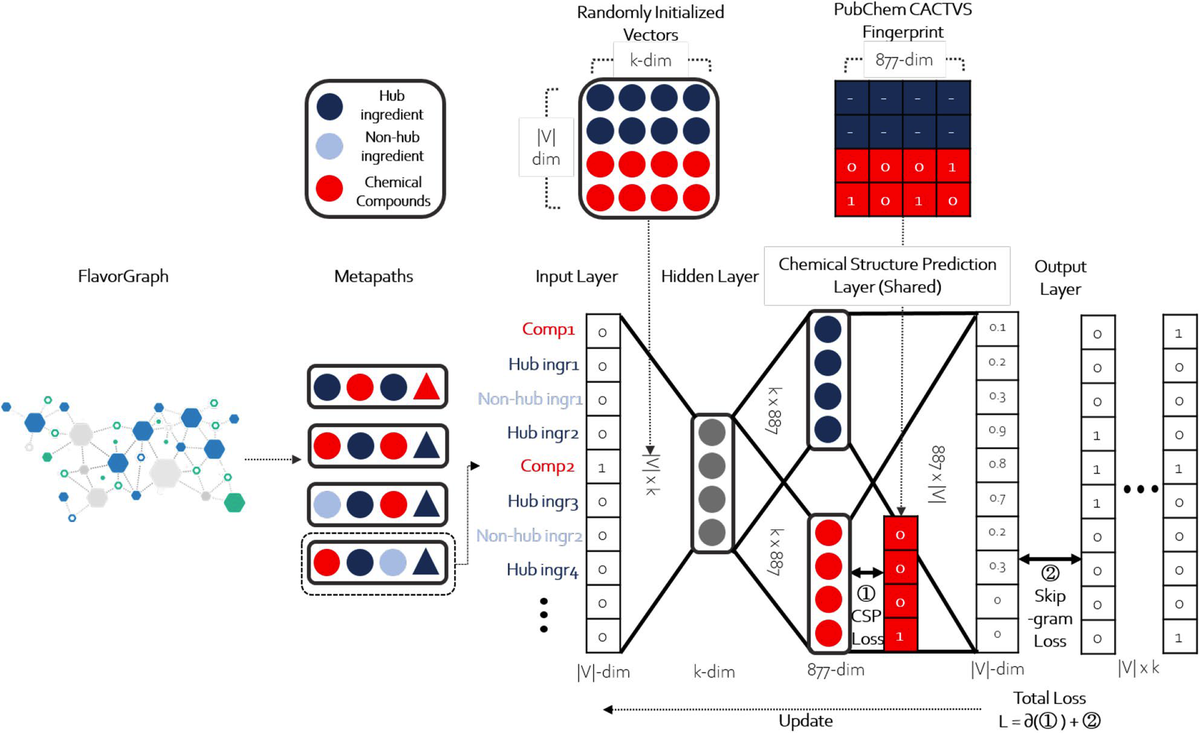
CSP層の追加
この研究のコアな提案としてmetapath2vecの学習に新たな層を追加している点.
元論文の図が以下で,中間層を経たものが新たに877次元の化学構造予測層を追加している.(これをCSP層と呼んでいる)場所としては①のところ.
FlavorGraphのアーキテクチャ
ここの877次元は化合物の線形表記方法であるFingerPrintsに沿った数だと思われる.化学には疎いので以下のサイトが分かりやすかった.
datachemeng.com
以下図は上サイトの引用から.
これらの情報をMetapath2vecの学習に混ぜることで,化合物の形を考慮しつつより高品質な食材ベクトルを得ることができるとしている.
結果
食材カテゴリにクラスタリング し,どれだけ食材を良く表せているかを測った.
肉とか魚とかの計8カテゴリを対象にしている.
kmeansでクラスタリング し,クラスタ 結果と元データのカテゴリの分布の一致度を測る正規化相互情報NMIを用いて評価する.
以下がその定義式.よく使われる相互情報量 を0から1の間に収まるように正規化したもの.(コードを見ると算術平均だったなので以下の式になる)
$$ NMI = \frac{2I(X;Y)}{H(X) + H(Y)} $$
結果を色々他の埋め込み手法と比べている.
手法
Random
FlavorDB
Im2Recipe
Node2vec/DeepWalk
Metapath2vec
Metapath2vec + CSP
次元
-
1645
300
300
300
300
精度
0.111
0.272
0.079
0.079
0.286
0.309
Random:ランダムベクトル
FlavorDB:グラフ構築元となっているデータから化合物が含まれているかどうかのバイナリを食材特徴量としている
Im2Recipe:これもデータ元となっているRecipe1Mのデータからテキスト埋め込みをしている
node2vec:構築したグラフにnode2vecを適応
metapath2vec:構築したグラフにmetapath2vecを適応
metapath2vec+CSP:この研究の提案
結果,CSPを追加した提案手法の精度が一番高いとしている.
何ができるのか
食材の分散表現を作って嬉しいこととして食材の演算.
この研究している考察の一つとして,食材+食材をしたベクトルで類似度検索をしたものを挙げている.
(類似度の計算方法は一般的なcos類似度)
その例が以下の表.
食材の演算
一列目は単にアイスクリームとの類似度を測っているだけだけど,2行目3行目はアイスとイチゴ,チョコを足した時を示している.
結果のアイス+イチゴを見ると"strawberry_gelatin"とか"strawberry_preserve"とかのいちご系が推薦できていることがわかる.
あと全体的に似たジャンルの食材が推薦できていることから,食合せの推薦とかに使えるのでは?
あと演算することができるので三つ以上とか引き算とか色々応用先がありそう.
その他
類似度検索とか未知ペアリング予測などの考察をしている.
詳細は元論文を読んでください.
気になった点
まず埋め込み手法が少し古い気がする.グラフ埋め込み手法は結構盛んに行われている分野なので,今一番精度の良いものに入れてみてどうなるのか気になる.
あと評価がクラスタリング なのも少し微妙.分布を見ていて,そのクラスタ 番号と食カテゴリが一致しているとは言えないので他クラス分類とかの方がいいのでは(Metapath2vecでの評価は多項ロジスティック回帰だった)
まとめ
FlavorGraphの論文の内容を軽くまとめた.
化合物との関係性をグラフで表現したものとしては革新的であり,著者が言うとおりまだまだな発展の余地が分野であると言える.
ただ食材というレシピ研究の基本がうまく行けば後続の応用タスクへの貢献も見えるので今後の展開に期待.
Github にコードが公開されている.
気になる中身などは実際に動かしてみた方が早いかもしれない.
python とかpytouchのバージョンが少し古いので注意.
github.com